
[Reactive] Reactive Programming 과 Reactive Stream
SightStudio
·2020. 8. 8. 23:55
Spring Webflux를 사용하면서 Reactive Programming 과 Reactive Strem에
대해 공부했던 부분을 정리합니다.
1. 리엑티브 프로그래밍이란?
단순히 이름만 듣고서는 어떤 뜻인지 정확하게 와닫지 않습니다..
[위키 피디아] 에서는 리엑티브 프로그래밍을 다음과 같이 정의하고 있습니다.
In computing, reactive programming is a declarative programming paradigm concerned with
data streams and the propagation of change. With this paradigm it is possible to express static
(e.g., arrays) or dynamic (e.g., event emitters) data streams with ease, and also communicate that
an inferred dependency within the associated execution model exists, which facilitates the automatic
propagation of the changed data flow.
위의 내용을 보아, 리엑티브 프로그래밍은 선언적 프로그래밍의 한 종류이고,
데이터의 흐름을 먼저 정의하고, 데이터가 변경되었을 때 이에 대한 연산이 전파되면서
데이터를 스트림 형태로 처리하는 방식을 말합니다.
선언적 프로그래밍 [Imperative]이란, 우리가 일일히 코드를 입력하는
명령형 프로그래밍 [Declarative]과는 달리 행위를 선언만 하는 프로그래밍 형태를 말합니다.
대표적으로 함수형 프로그래밍의 map, reduce 연산이 이에 해당합니다.
2. 등장 배경
왜 써야 할까요? 기존에 서버는 요청을 어떻게 처리하였을까요?
전통적인 아키텍처에서는 동기 블로킹방식을 사용합니다.
간단하게 하나의 요청에 대해 하나의 스레드를 통해 처리하는 방법입니다.
모든 데이터를 가져와서 처리할 때까지 해당 스레드를 블로킹합니다.
구현도 쉽고, 안정성도 어느정도 보장됩니다.
하지만 한번에 많은 요청이 들어올 경우, 우리가 계산했던 TPS 만큼의 처리량이 나오지 않고,
서버는 장애에 빠질 수 있습니다.
3. 비교
- 전통적인 데이터 처리 방식 [ 1 request == 1 thread ]
위의 설명처럼 기존의 방식에서는 하나의 요청에 대해, 하나의 스레드가 할당되는 방식입니다.
이런 아키텍처에서는 스레드를 만드는 시간을 줄이기 위해,
스레드풀을 만들어 처리합니다. 하지만 스레드풀을 넘어서는 요청이 들어올때는 어떻게 될까요?
아래는 전통적인 모델인 Tomcat - Spring MVC 환경에서 부하테스트를 주었을 때의 스레드들의 상태입니다.
빨간색은 parked() 상태로써, 요청을 처리중이라 다른 일을 하지 못하는 블로킹 상태입니다.
아래처럼 모든 스레드가 이런 상태면 어떻게 될까요?
이후에 들어오는 요청들은 블로킹 상태에 되어있다가 결국 처리되지 못하고
timeout되어 요청 처리에 실패할 것입니다.
즉, 처리할 스레드가 부족해서 요청을 처리하지 못합니다. CPU와 메모리가 충분한데도 말이죠.

그냥 스레드 개수를 늘리거나, Scale-up, Scale-out 하면 안되나요?
스레드를 무작정 늘릴 경우, 이번에는 스레드가 충분함에도 불구하고 과도한 컨텍스트 스위칭이 발생하여
CPU와 메모리 때문에 처리율이 떨어질 수 있습니다.
컨텍스트 스위칭이란, 스레드의 상태를 저장하고 다른 스레드를 가져와서 실행하는 행위입니다.
프로세스의 정보는 PCB안에 저장되어 있고, 이 PCB안에 현재 실행중인 스레드 정보들이 있습니다.
여기서 CPU는 기존에 처리하던 스레드의 상태를 저장하고 다른 스레드를 상태를 로드하여 처리합니다.
당연히 이때 컴퓨팅 연산이 필요하며, 스레드가 많을 수록 이런 연산은 많아 질 수 밖에 없습니다.
Scale up과 Scale out이 하나의 해결책이 될 수 있지만,
결과적으로 위의 문제가 근본적으로 해결된 부분이 아니기 때문에 인프라의 자원을 낭비하게 될 것입니다.
- Reactive Stream에서의 데이터 처리 방식 [ many request == 1 thread ]
그렇다면 Reactive Programming에서는 어떨까요?
다음은 리엑티브 프로그래밍 기반의 Netty - Spring Webflux 환경에서 부하테스트를 했을 때
스레드들의 상태입니다. 보시다 시피 많은 스레드들을 만들지 않습니다.
netty 기반 웹플럭스에서는 cpu코어 * 2개의 스레드만 사용해서 요청을 처리합니다.
앞단에서 요청을 받는 reactor-http-nio 스레드들은 적은 수를 유지하면서, 연산을
뒤의 이벤트루프에게 위임하고 결과값만 받아서 처리합니다.
결과적으로는 컨텍스트 스위칭을 줄일 수 있고, 더 많은 요청을 처리할 수 있습니다.
자바 nio의 논블로킹 I/O (selector)를 사용하여 이를 가능하게 하지만
글의 범위를 벗어나기 때문에 따로 설명하지는 않겠습니다. (linux 상에서는 epoll을 직접 사용합니다.)
3. 리엑티브 프로그래밍의 기반 기술
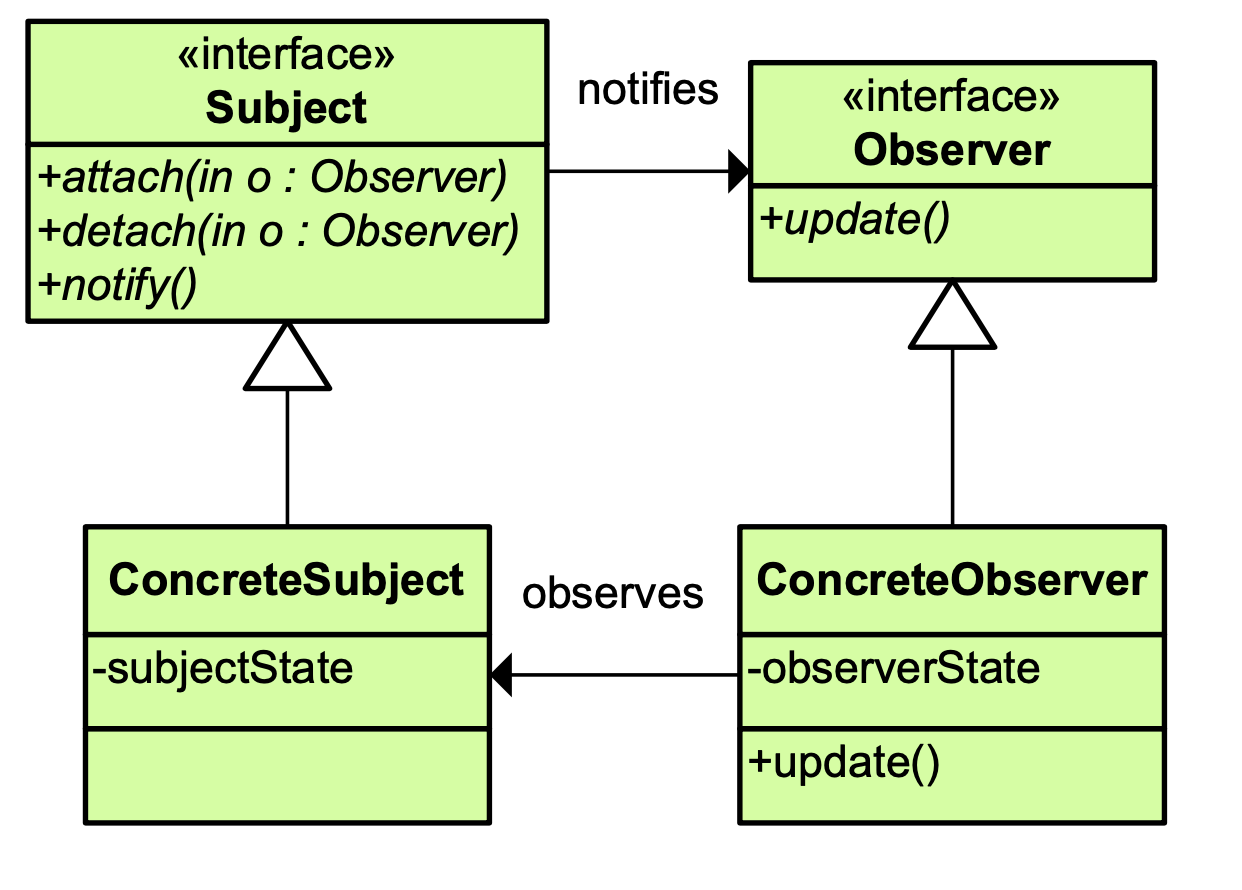
- Observer Pattern [관찰자 패턴]
옵저버 패턴은 일대다의 관련성을 갖는 객체들 중 한 객체의 상태가 변하면 다른 모든 객체에
그 사항을 알리고 필요한 수정이 자동으로 이루어지도록 할 수 있도록 하는 디자인 패턴입니다.
관찰자 패턴에서는 ConcreteSubject의 상태에 변경이 일어났을 때 Subject의 notify() 함수를 통해
Observer의 상태를 변경합니다. 옵저버 패턴은에서 Subject는 Observer의 상태를 고려하지 않고
이벤트를 보내기 때문에 [push 방식] 이라고 합니다.
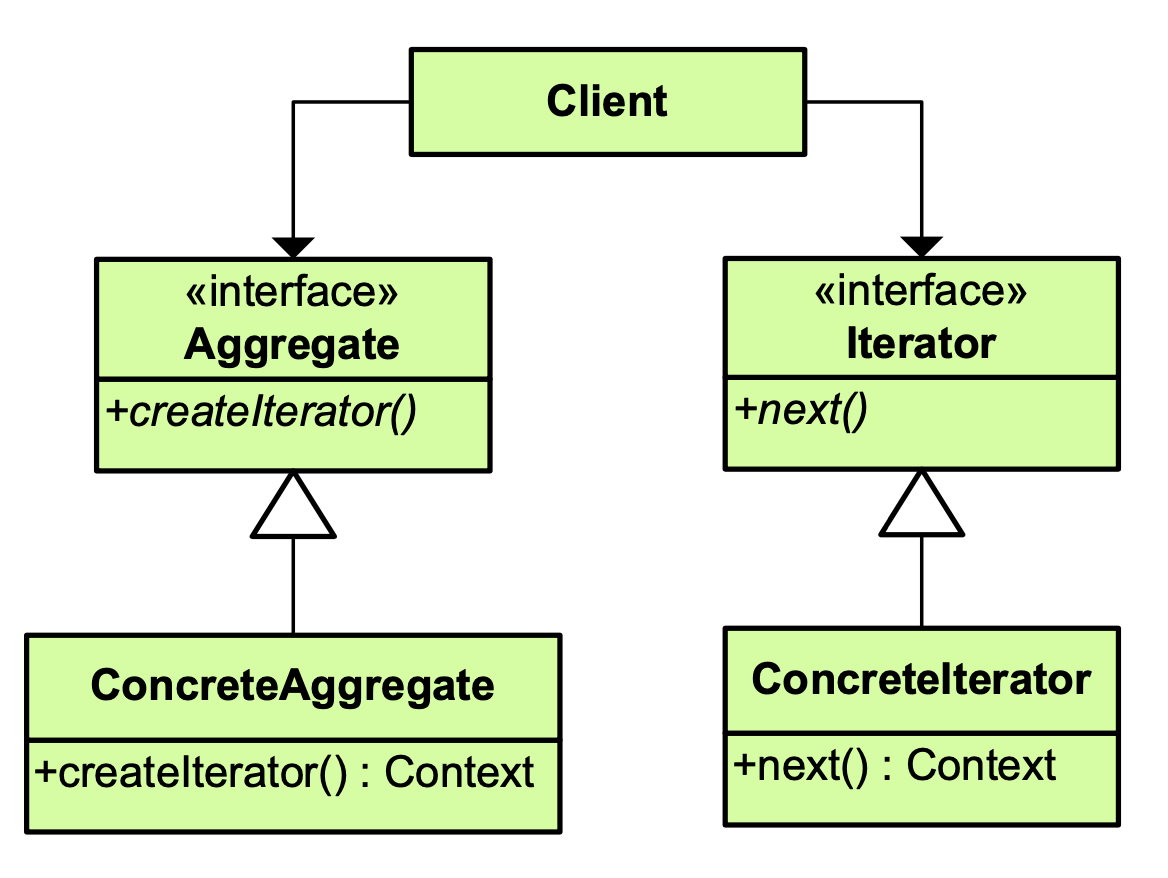
- Iterator 패턴 [반복자 패턴]
반복자 패턴은 컬렉션 구현 방법을 노출시키지 않으면서 컬랙션 안에 들어있는
모든 엘리먼트에에 접근할 수 있는 방식을 구현한 패턴입니다.
옵저버 패턴과 달리 반복자 패턴은 next()를 통해 데이터를 리턴받아서 [pull 방식] 이라고 합니다.
4. 리엑티브 스트림
Reactive Stream이란 논블로킹과 백프레셔를 갖춘 비동기 스트림 처리를 위한 표준입니다.
[공식 홈페이지]에서는 네트워크 뿐 아니라, JVM 과 JS같은 런타임 환경에서도
돌아가도록하는것이 목표라고 적혀있습니다.
더 자세한 API 명세는 [이 곳] 에서 확인할 수 있습니다.
Reactive Stream = Observer Pattern + Iterator Pattern
아래와 같은 특징 때문에 리엑티브 스트림은 옵저버 패턴과 반복자 패턴의 결합이라고 합니다.
이걸 한마디로 표현하면 '내가 처리할 수 있는 양만큼만 가져와서 처리한다' 라고 봐야겠네요.
리엑티브 스트림과 옵저버 패턴의 차이점
- [Backpressure] Hybrid Pull / Push
기존 옵저버 패턴에서 데이터 변화는 Publisher[Subject]가 Subscriber[Observer] 에게
데이터를 밀어넣는 [notify] 형태였습니다.
하지만 1초에 10개 밖에 요청을 처리하지 못하는 Subscriber에게 Publisher가
더 많은 이벤트를 보내면 어떻게 될까요?
당연히 요청은 처리되지 못할 것이고, 이를 위해 버퍼를 둔다고 한들
요청이 쌓이는건 똑같기 때문에 문제는 해결되지 않을 것입니다.
Reactive Stream에서는 이 문제를 해결하기 위해 Backpressure를 도입하였습니다.
Backpressure 란 배압이란 뜻으로, 배관등에서 과투입되는걸 막기위해
역으로 압력을 주어 압력을 약화 시키는 것을 말합니다.
소프트웨어 레벨에서도 똑같이 작용합니다.
요청이 과투입되는어 Subcriber가 오버플로우 되는것을 막기 위한 용도로 Backpressure가 사용됩니다.
이 부분은 말로만 하면 어떤 말인지 이해가 잘 가지 않으니, 코드 레벨에서 살펴보겠습니다.
다음은 Reactive Stream의 JVM 구현체중 하나인 Project Reactor의 코드입니다.
import org.junit.jupiter.api.Test;
import org.reactivestreams.Subscriber;
import org.reactivestreams.Subscription;
import reactor.core.publisher.Flux;
public class BackPressureTest {
@Test
public void subscribeTest() {
Flux.range(0, 1000)
.log()
.subscribe(new MySubscriber());
}
}
class MySubscriber implements Subscriber<Object> {
private Subscription subscription;
private int requestCnt;
@Override
public void onSubscribe(Subscription s) {
this.subscription = s;
// 최초 subscribe시 10개만 요청
this.subscription.request(10);
}
@Override
public void onNext(Object object) {
// 이후 전부 가져올때까지 10개씩 반복요청
requestCnt++;
if(requestCnt % 10 == 0) {
this.subscription.request(10);
}
}
@Override
public void onError(Throwable t) {
}
@Override
public void onComplete() {
System.out.println("Subscribe Finished");
}
}실행결과
Publisher가 subscribe 하면 onSubscribe를 통해
Subscription 객체를 가져옵니다..
여기서 한번에 데이터를 다 가져오는 것이 아니라,
onNext()를 통해 Subscription의 데이터를
필요한 만큼 나눠서 가져옵니다.
왜 Observer + Iterator 패턴이라는지 알 수 있는 부분입니다.
이를 통해 Subscriber가 수용할 수 있는 만큼
데이터를 가지고 올 수 있습니다.
이게 Backpressure의 기본 개념입니다.
(물론 webflux 에서는 자체적으로 subscriber를 만들어줍니다.)
물론 Subscriber의 부하를 유지할 수 없을 경우를 대비해 큐에 임시 저장하여 버퍼링을 할 수도 있습니다.
import org.junit.jupiter.api.Test;
import org.junitpioneer.jupiter.SetSystemProperty;
import reactor.core.publisher.Flux;
import reactor.core.publisher.FluxSink;
import reactor.core.scheduler.Schedulers;
public class BackpressureBufferStrategyTest {
@Test
@SetSystemProperty(key = "reactor.bufferSize.small", value = "20")
public void 고정_길이_버퍼() throws InterruptedException {
Flux<Object> fluxAsyncBackup = Flux.create(emitter -> {
for (int i = 0; i < 50; i++) {
emitter.next(i);
}
emitter.complete();
}, FluxSink.OverflowStrategy.BUFFER) // 오버플로우시 버퍼링
.onBackpressureBuffer(20); // 버퍼링 사이즈 20 (고정길이)
fluxAsyncBackup
.subscribeOn(Schedulers.elastic())
.publishOn(Schedulers.elastic())
.subscribe(reqNum -> {
System.out.printf("%s | Received = %s\n",
Thread.currentThread().getName(), reqNum);
// 요청 처리가 1초가 걸리는 느린 Subscriber 재현
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, error ->
System.out.printf("%s | Error = %s %s\n" ,
Thread.currentThread().getName(), error.getClass().getSimpleName(), error.getMessage())
);
Thread.sleep(100000);
}
}
위과 같이 하나의 요청이 1초가 걸리는 느린
Subscriber가 존재할 경우, 요청에 대해
버퍼링(큐잉)을 통헤 나머지 이벤트를
저장할 수 있습니다.
해당 코드는 기본적으로 20사이즈의 요청을 처리하지만,
추가로 20사이즈 버퍼에 이벤트를 저장하여
총 40개의 요청을 처리할 수 있었습니다.
고정길이 버퍼이기 때문에 버퍼 사이즈를 40보다 많은 (50개)
요청이 들어왔기 때문에 오버플로 익셉션이 발생하였습니다.
이를 가변길이로 변환하려면 .onBackpressureBuffer(20) 부분을 지워주면 됩니다.
단, 가변길이의 경우 너무 많은 버퍼링과, 배열의 복제과정으로 인해
OutOfMemory Exception이 발생할 수 있습니다.
OverflowStrategy.BUFFER 이외에도 허용치를 넘어서는 요청이 들어오면 버리는 DROP,
가장 최신것만 가져오는 LATEST 등 여러 전략이 있습니다.
- Reactive Stream의 흐름도 marble diagram
reactive stream은 다음과 같이 마블 다이어그램 형태로 표현합니다.
5. 후기
Spring Webflux를 배우기 위해 공부했던 개념이였지만, reactive stream 자체가
생각보다 알아야할 개념들이 많고 복잡합니다.
아직 모르는 부분이 많고, 공부해야할 부분이 많은것 같네요.
나머지는 다음에 정리해야겠습니다.
6. 혼란스러웠던 개념들
- Reactive Programming 과 Reactive System
리엑티브 프로그래밍을 공부하다 보면 다음과 같은 혼선을 유발하는 용어들이 발생합니다.
조금만 찾아봐도 Reactive Programming은 Event-Driven인데 Reactive System은 Message-Driven
이라는 글이 수두룩하게 나옵니다. 이는 하나의 에플리케이션 관점, 전체 아키텍처의 관점으로 구분하는 할 수 있습니다.
리엑티브 프로그래밍을 한다고 시스템 아키텍처를 리엑티브 시스템으로 만들 수는 없습니다.
리엑티브 시스템이 되기 위해서는 각 컴포넌트들이 메세지 브로커등을 통해서 message 기반으로 통신해야합니다.
또한 요청에 대한 탄력성과 유연성이 보장되어야합니다.
자세한 내용은 공식 문서를 참고해주세요
https://reactivemanifesto.org/ko
리액티브 선언문
탄력성(Resilient): 시스템이 장애 에 직면하더라도 응답성을 유지 하는 것을 탄력성이 있다고 합니다. 탄력성은 고가용성 시스템, 미션 크리티컬 시스템에만 적용되지 않습니다. 탄력성이 없는 시
reactivemanifesto.org
즉, 정리하자면 아래와 같이 되겠군요.
| Reactive Programming | Reactive System |
| Event-Driven | Message-Driven |
| Observer Pattern | Pub - Sub Pattern |
잘못된 부분에 대한 지적은 감사히 받겠습니다!
출저
실전! 스프링 5를 활용한 리액티브 프로그래밍 - 교보문고
오늘날 기업은 어떤 상황에도 높은 응답성을 유지할 수 있는 새로운 유형의 시스템이 필요합니다. 리액티브 프로그래밍을 이용하면 이를 달성할 수 있습니다. 이러한 시스템 개발은 복잡하며 ��
www.kyobobook.co.kr
projectreactor.io/docs/core/release/reference/
Reactor 3 Reference Guide
10:45:20.200 [main] INFO reactor.Flux.Range.1 - | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription) (1) 10:45:20.205 [main] INFO reactor.Flux.Range.1 - | request(unbounded) (2) 10:45:20.205 [main] INFO reactor.Flux.Range.1 - | onNext(1) (3) 1
projectreactor.io
'개발 > Java' 카테고리의 다른 글
| Optional은 정말로 필요한가? (feat. JSpecify) (3) | 2024.12.29 |
|---|---|
| jOOQ 를 좀 더 알아보자 (1) | 2022.01.03 |
| [GC] 1. JVM 가비지 컬랙터란? (0) | 2020.08.19 |
| [Java] NIO, 그리고 Netty (5) | 2020.08.12 |





