
Galera Cluster에 대해 알아보자
SightStudio
·2021. 6. 19. 07:44

도입
현재 다니는 회사에서 RDBMS로 MariaDB를 사용하고 있습니다.
서비스가 규모가 있다보니 단일 DB로는 버틸 수 없기 때문에
Galera Cluster로 클러스터를 구성하여 사용하고있습니다.
오늘은 MariaDB/MySQL에서 사용되는 동기식 멀티마스터 클러스터인
Galera Cluster에 대해 알아보도록 하겠습니다.
갈레라 클러스터를 간단히 도커로 세팅을 해보았습니다.
[Github 링크]
Galera Cluster 란
갈레라 클러스터는 동기 방식의 복제구조를 사용하는 멀티마스터 RDB 클러스터입니다.
단, 논리적으로는 완전 동기이지만 실제 write 와 tablespace에 commit하는 과정이 별개이고
각 노드간에는 비동기로 동작합니다.
갈레라 클러스터에서 이를 virtually synchronous replication 라고 부릅니다.
Master Slave 구성의 Replication 과는 다르게 모든 노드에서 Write가 가능합니다.
하지만 아래 후술할 이유 때문에 Write 노드는 반드시 하나여야만 합니다.
동기 복제 방식
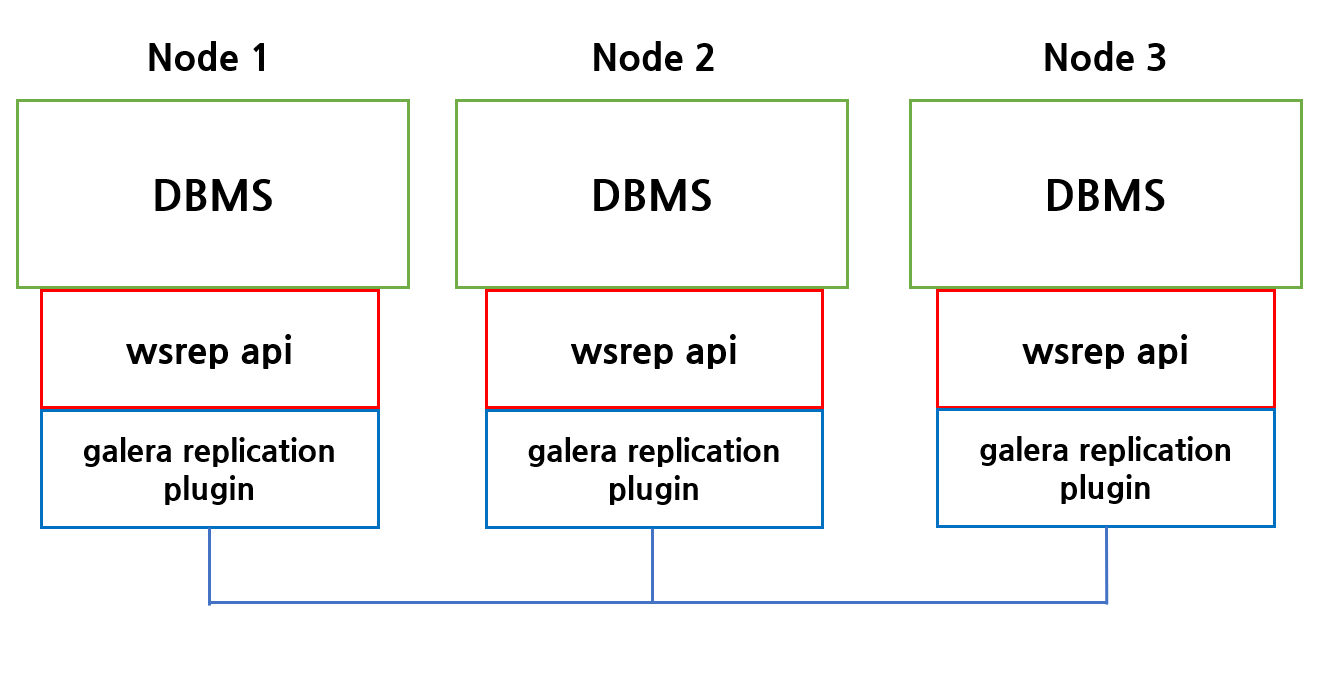
Galera Cluster는 Write-Set Replication API (이하 wsrep api) 를 통해 각 노드와 데이터를 동기화합니다.
다만 wsrep api는 dbms 간 복제를 위한 인터페이스이고,
실제 구현부는 아래의 galera replication plugin 에서 이루어집니다.
각 노드에 쓰기나 업데이트가 발생할 경우 위의 노드간에 데이터를 복제하고 업데이트 내용을
아래 설명할 [GCache] 라는 영역에 저장합니다.
인증 기반 복제
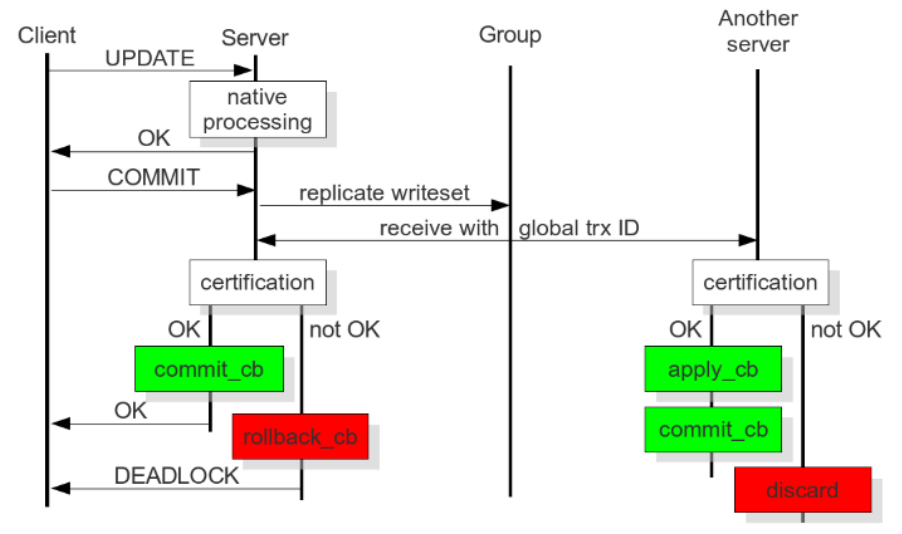
Certification-Based Replication
조금 더 세부적으로 보자면 노드에 트랜잭션이 발생 후에 commit을 하게되면
바로 디스크에 쓰지 않고 다른 노드로 복제요청을 합니다.
이후 모든 노드들이 GTID 기반 인증을 한 후에야 디스크에 데이터를 쓰게됩니다.
certification 과정에서 PK 기반으로 writeset에 무결성 검사를 하기 때문에 반드시 PK가 있어야합니다.
(당연한 말이지만요..)
이때 certification이 실패하게되면 최초 요청을 받은 노드는 데드락이 발생하게됩니다.
(PK가 없거나, 아래의 first committer win 의 경우 등등.. )
구조를 보시면 아시겠지만, Optimistic Lock과 유사하게
실제 certification 하기 전까지 충돌이 나지 않는다고 가정하고 진행됩니다.
그래서 공식 문서에서는 이 과정을 Optimistic Execution 이라고 표현합니다.
갈레라 클러스터는 이러한 행위를 통틀어 [ 인증 기반 복제 ] 라고 부릅니다.
장단점
이러한 동작방식 덕분에 모든 노드의 데이터가 일관성있게 저장된다는 장점이 있습니다.
(Master-Slave 형태의 비동기 복제보다는 일관성이 있다)
그리고 모든 노드가 (이론상으론) 쓰기가 가능하기 때문에 모든 노드가 죽기전까지는
서비스가 장애에 대응 할 수 있습니다.
(정확히는 정족수의 개수까지만 노드가 살아있다면)
하지만 단점도 만만치 않습니다. 동기식 복제 구조때문에 쓰기가 많이 발생할 경우,
다른 아키텍처보다 성능이 떨어지며, 스케일 아웃하기에도 한계가 느겨질 수 있습니다.
또한 인증에 실패할 경우 발생하는 데드락도 운영에 치명적입니다. ( 잘 모르고 썼을 경우 )
First Committer Win 정책
갈레라 클러스터에서 쓰기 노드를 하나만 구성해야하는 이유입니다.
갈레라 클러스터는 노드간의 데이터 동기화를 위해 "first committer win" 라는 규칙을 따릅니다.
다른 노드간에 x 락이 발생할 경우, 가장 먼저 commit한 노드의 데이터를 받아들이고,
이후에 커밋된 노드는 데드락이 발생합니다.

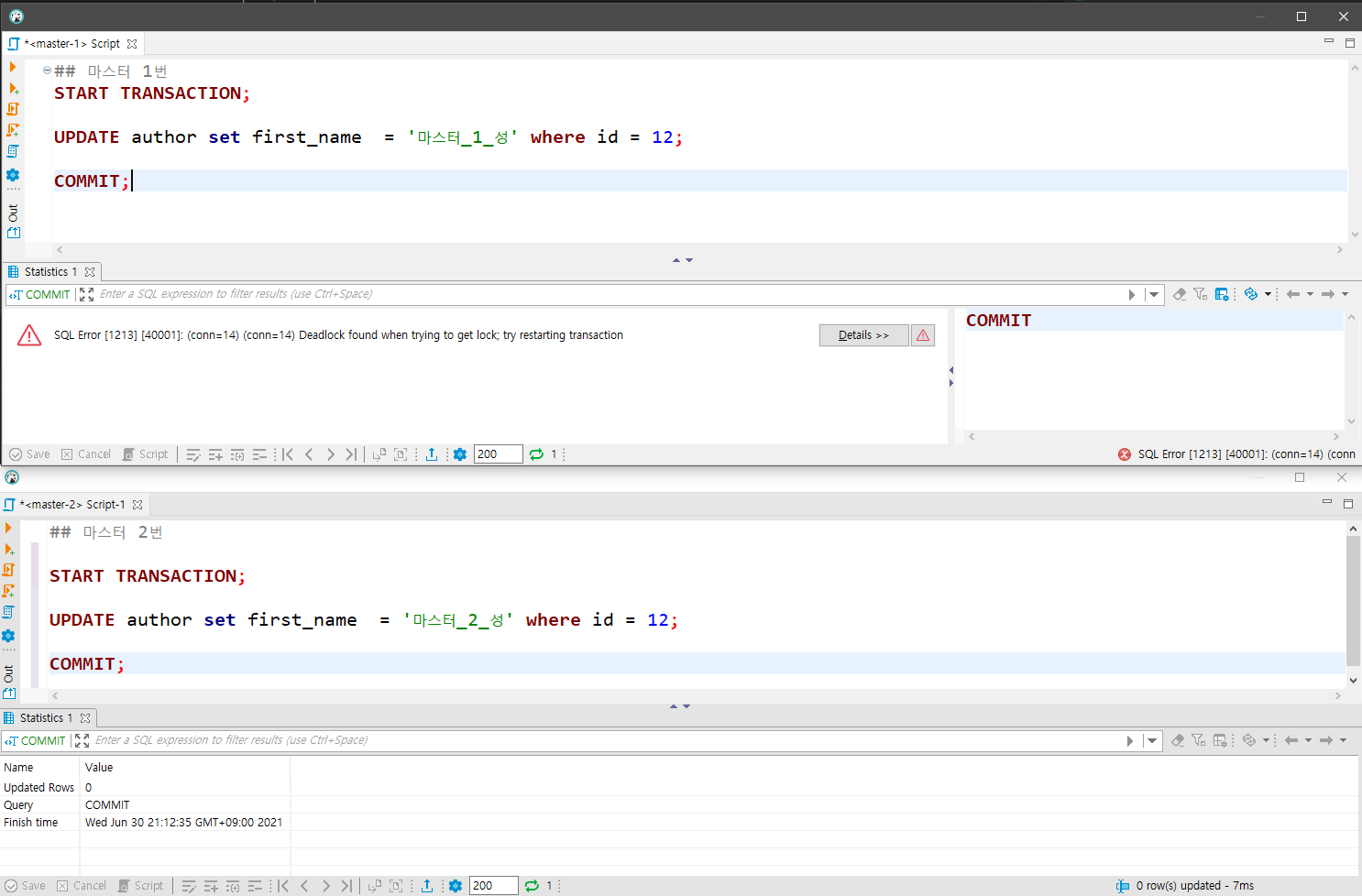
위의 사진이 만약 단일 노드에서 발생했을 경우, 간단히 X 락을 걸면되지만
다른 노드간에서 발생하기 때문에 X락만으로는 해결할 수 없습니다.
만약 3번에서 커밋이 진행된다면 어떻게 될까요?
2번이 실행되고 다시 select를 할 경우, "마스터_1_성"으로 나와서 데이터의 정합성이 깨지게 됩니다.
이와 같은 상황을 막기위해 1번에서는 데드락이 발생하게되고, 마스터 1의 write-set은 무시됩니다.
실제로 위의 순서대로 진행하면 데드락이 발생하는 것을 확인 할 수 있습니다.
ISOLATION LEVEL
트랜잭션의 ISOLATION LEVEL은 유명한 개념이니 여기서 따로 설명하지 않습니다.
갈레라 클러스터에서의 ISOLATION LEVEL은
한 트랜잭션이 단일노드에서만 행해지는지, 클러스터간인지 구분해야합니다.
단일 노드
단일 노드에서 발생하는 트랜잭션은
> READ-UNCOMMITTED, READ-COMMITTED, REAPEATABLE-READ, SERIALIZABLE
4가지 모두 지원됩니다.
다중 노드
여러 노드가 트랜잭션에 참여할 경우, 위에 설명한 "first committer win"의 룰에 영향을 받습니다.
그리고 가장 강력한 격리 레벨인 "SERIALIZABLE"은 노드간 트랜잭션에서 지원되지 않습니다.
갈레라 클러스터는 READ-ONLY 트랜잭션에서 각 노드간에 read-set을 공유하는데
SERIALIZABLE 레벨에서는 이를 공유하지 않습니다.
[공식 문서]에서는 이를 SERIALIZABLE 레벨에서 읽기 잠금이 Replication에 의해 덮어씌여지는걸
막을 방법이 없어서 그렇다고 합니다.
Galera does not support SERIALIZABLE isolation in multi-master topology, because there is currently no means to protect read locks from being overwritten by the replication
상태 전송
노드가 추가 될 때 갈레라 클러스터는 기존에 데이터들을 상태를 복제하여 참여하는 노드에 전송합니다.
스냅샷을 전송하는 노드를 Donor, 스냅샷을 전달받아 새로이 참여하는 노드를 Joiner라고 부릅니다.
상태 전송시에는 노드 중에 Donor로 되어있는 설정된 노드의 데이터를 복제하여 전송합니다.
증분 상태 전송
[ IST ] Incremental State Transfers

IST 는 노드간에 전송되지 않은 데이터들만 찾아서 복제하는 방식입니다.
아래에 설명할 SST 방식 보다는 빠르지만, 항상 사용할 수는 없습니다.
그럼 이 "전송되지 않은 데이터" 들은 어떻게 체크할까요?
갈레라 클러스터는 이를 위해 [GCache] 라는 자체 메모리를 사용하는데요.
여기에다 write한 데이터들을 저장합니다. (write set)
GCache는 주로 메모리나, memory-mapped file로 물리적 디스크에 저장되며 디폴트 사이즈는 128M입니다.
이 범위를 넘어선 쓰기를 해야할 경우 IST 방식 대신 아래의 SST 방식으로 복제합니다.
스냅샷 상태 전송
[ SST ] State Snapshot Transfers
SST 방식은 Donor 노드에 있는 데이터 전체를 스냅샷상태로 복사하여 Joiner 노드로 복사합니다.
당연히 DB의 데이터가 클 경우 SST로 인한 복제시간이 오래걸리기 때문에 피해야합니다.
완전한 신규 노드이거나 (.grastate파일이 없는 상태) , GCache 용량 초과로 인해 위의 IST 방식을
사용할 수 없을 때 발생됩니다.
mysqldump, rsync, clone, xtradump 4가지 방식이 있으며,
이때 Donor 노드는 READ-ONLY 상태가 됩니다.
자세한 설정은 아래 공식문서에 나와있습니다.

[마스터 - 1] Doner 노드 (최초 노드)

[마스터 - 2] Joiner - 노드 rsync 방식으로 마스터 1로부터 스냅샷 복제

[마스터 - 3] Joiner - 노드 rsync 방식으로 마스터 1로부터 스냅샷 복제

[ Split Brain ] Quorum Components
Quorum : 정속수
서비스를 운영하다보면 다양한 이유로 장애가 발생 할 수 있습니다.
[ Split Brain ] 은 네트워크로 인해 발생하는 장애중 하나인데요.
네트워크의 일부 연결이 끊김으로 인해 클러스터가 나뉘는 현상을 말합니다.
이때 클러스터가 모두 연결되지 않아 쪼개진 클러스터들이 스스로를 원본 (Primary)라고 생각합니다.

갈레라 클러스터는 이런 상황이 발생할 경우
나뉘어진 클러스터중 노드 수가 많은 클러스터만 남기고 모두 중지시킵니다.
이때 제일 노드가 많은 클러스터를 PRIMARY 라고하며, 나머지를 모두 NON-PRIMARY로 부릅니다.
그러면 궁금증이 하나 생깁니다. 노드가 짝수일 때 절반으로 나뉘어지면 어떻게될까요?
갈레라 클러스터는 이 경우 모두 NON-PRIMARY 로 인식하고 모든 노드를 중지시킵니다.
그렇다고 강제로 DB 노드를 추가하거나 줄이기에는 부담이 될 수 있습니다.
이런 상황을 방지하기 위해 [갈레라 아비터] 라는 컴포넌트를 제공합니다.
갈레라 아비터는 복제에 참여하지는 않지만, 위와 같은 split brain 상황에서
Quorum 노드로 참여하여 노드 정족수 계산시 홀수를 유지시켜줍니다.


기타 주의 사항
1. Galera Cluster는 MyISAM 일부와 InnoDB만을 지원합니다.
2. 멀티 마스터지만, RW 하나와 RO 여러대로 구성하는게 일반적이며,
이때 RO는 HA-PROXY 등으로 분산처리가 필요합니다.
마치며
이상 갈레라 클러스터에 대한 전반적인 특징을 알아보았습니다.
갈레라의 경우 많은 자료가 없어서 공식문서를 많이 볼 수 밖에 없네요. (공식문서도 빈약한점이 조금 있군요 ㅜㅜ)
반쪽짜리 멀티 마스터라는 신기한 구조를 띄고 있네요.
더 심오한 이슈를 겪게되면 그때 다시 블로그에 글을 써봐야겠습니다.
REFERENCE
https://galeracluster.com/library/galera-documentation.pdf
https://galeracluster.com/library/documentation/
'개발 > RDB' 카테고리의 다른 글
| [MySQL] 설치 후 세팅 (한글, 시간등등) (1) | 2020.08.13 |
|---|---|
| [Oracle] MacOS에서 오라클 사용하기 (0) | 2020.08.08 |



