
프로메테우스에 대해 알아보자
SightStudio
·2021. 8. 7. 19:56

도입
회사에서 서버 개발자로써 생활하다보니 다양한 장애 이슈를 마주하게 되었고, 이를 해결하다 보니
메트릭을 수집하여 서버의 상태를 확인 할 수 있는 모니터링 시스템이 필요하게 되었습니다.
이를 위해 프로메테우스 + 그라파나를 통해 메트릭 모니터링 시스템을 구축하였고,
그 과정에서 공부한 점을 정리하게 되었습니다.
관련 부분은 [Github] 에서 확인 할 수 있습니다.
프로메테우스란?
프로메테우스란 SoundCloud사에서 만든 오픈소스 모니터링 시스템입니다.
로그가 아닌 시스템의 상태를 나타내는 메트릭 정보를 시계열 형태로 저장하며
PromQL 이라는 SQL 형태로 저장할 수 있습니다.
쿠버네티스 환경에서도 프로메테우스 사용을 장려하고 있으며,
주로 Grafana를 통해 프로메테우스의 메트릭 정보를 시각화 합니다.
프로메테우스 구조
아래는 프로메테우스의 구조입니다.
구조는 생각보다 단순하며 실제로 구축하는데도 큰 어려움이 없었던듯합니다.

1. Service Discovery
프로메테우스는 메트릭 수집대상의 목록과 IP 주소등을 가지고 있어야합니다.
prometheus.yml에 DNS를 등록을 하게나, k8s 환경에서는 컨피그 맵등을 통해 메트릭을
수집 할 서비스 목록을 가져올 수 있습니다.
2. Prometheus Server
프로메테우스의 주요 기능을 수행하는 요소입니다. 크게는 Retrieval, Storage, PromQL 로 구성되어있습니다.
[Retrieval]
아래 설명할 Exporter들로 부터 가져오는 메트릭을 주기적으로 가져오는 역할을 합니다.
특이한 점은 프로메테우스는 기본적으로 에이전트들이 프로메테우스로 Push 하는 방식이 아닌
Retrieval을 통해 각 Exporter들을 Pulling 하는 방식입니다. 즉 전자보다 트래픽의 부담이 덜합니다.
[Storage]
수집한 메트릭들을 시계열 형태의 데이터로 저장합니다.
여기서 중요한 점이 하나 있는데, 프로메테우스는 로컬 디스크에 저장합니다.
즉 기본적으로는 스케일 아웃이 불가능한 구조를 가지고 있습니다.
( 대신 설치가 매우 쉬우며, HA 경우는 Thanos 와 같은 오픈소수 솔루션을 사용할 수 있습니다.)
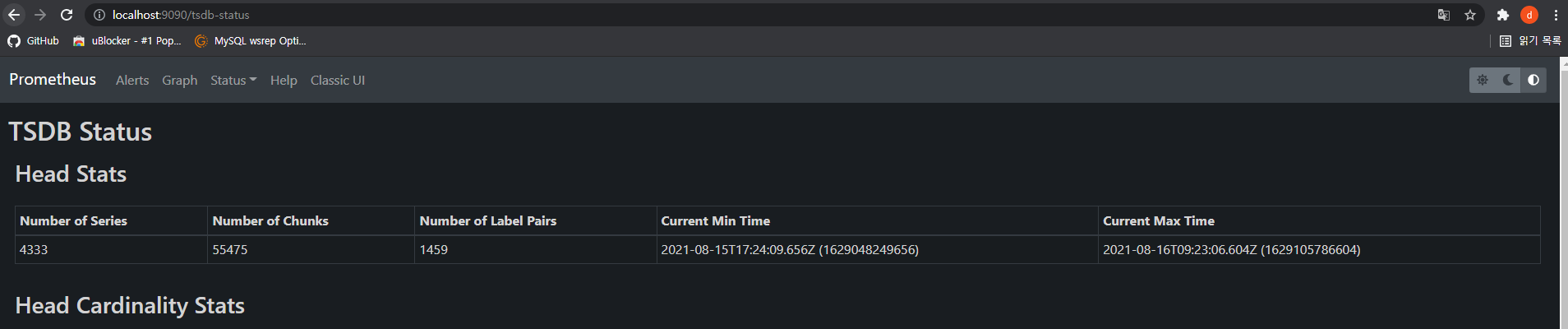
데이터는 TSDB (Time Series Database) 형태로 저장되며 WebUI 등에서 상태를 확인할 수 있습니다.
[PromQL]
우리가 RDBMS에 데이터를 저장하고 해당 데이터들을 가져올 때와 비슷하게
프로메테우스에서는 저장된 데이터들을 가공할 수 있도록 PromQL 이라는
Query Language를 지원합니다.
아래사진은 PromQL로 MariaDB에 분당 쿼리 처리량을 프로메테우스 WebUI 에서 질의한 형태입니다.
(Galera Cluster로 3개 노드가 클러스터링 되어있어 3개가 나옵니다)
rate(mysql_global_status_queries[1m])

3. Jobs / Exporter
Exporter는 타겟 시스템의 메트릭을 읽어서 프로메테우스 서버가 가져 갈 수 있는 메트릭 형태로 가공하여
내보내주는 역할을 합니다. 이를 통해 프로메테우스 서버는 각 Exporter로 HTTP GET 요청을 통해
메트릭을 수집합니다.
예를 들어 MySQL/MariaDB 용 Exporter인 [ mysqld_exporter ] 의 경우
아래와 같이 프로메테우스가 읽을 수 있는 메트릭 형태로 응답을 내려줍니다.
프로메테우스가 읽을 수 있는 메트릭의 형식이 정해져 있으며 해당 형식에 맞춰서 작성할 경우
공식 exporter 외에도 추가로 만들 수 있습니다. [ 형식 링크 ]

4. Pushgateway
배치와 스케줄 작업들은 일회성 형태를 띄고있어 Pull 방식보다는 메트릭을 프로메테우스로 보내는
Push 형태에 더 적합할 수 있습니다. 이 경우에는 Pushgateway를 통해 서버로 메트릭을 push 할 수 있습니다.
[ 공식 문서 ] 를 참고하면 Pushgateway가 효과적인 케이스는 서비스 레벨의 배치성 작업밖에 없다고 하는군요.
5. Alert Manager
프로메테우스에 경보 규칙을 설정하면, 해당 조건에 맞게 경보 이벤트를 발생 시킬 수 있습니다.
Pushover (웹훅) , SMTP (email), Slack 등 여러 매체로 경보를 보낼 수 있습니다.
다만 그라파나에도 이와 같은 Alert 시스템이 존재해서 어떤 걸 사용해야할지는 고민해봐야겠네요.
프로메테우스 단점
프로메테우스는 장점이 명확한만큼 한계치도 명확하게 존재합니다.
1. 메트릭은 근사치
프로메테우스는 주기적으로 풀링을 통해 exporter들로부터 메트릭을 수집하기 때문에 실시간이 아닙니다.
이는 Pulling 방식을 통해 부하를 줄이는 대신 얻을 수 있는 트레이드 오프 같네요.
2. HA, 스케일링의 어려움
프로메테우스의 메트릭 데이터는 싱글호스트 기반의 메모리와 로컬디스크에 저장됩니다.
싱글 호스트 기반으로 설계되어 스케일링이 불가능하고, 디스크를 늘리는 방법이 유일한 해결책입니다.
HA 구성의 경우 여러 오픈소스 프로젝트가 있는데 [Thanos] 등의 오픈소스가 주로 사용됩니다.
이부분은 나중에 봐야겠네요.
마치며
다른 시스템을 구축하면서 상대적으로 쉽다는 느낌을 많이 받았습니다.
회사에서 이런 메트릭 정보를 모니터링하는 시스템이 필요하게 되었는데 도입 할 수 있었으면 좋겠네요.
'개발 > devops' 카테고리의 다른 글
| 로드밸런서에 대해 알아보자 (3) | 2021.10.13 |
|---|---|
| [k8s] 5. 서비스 - 파드를 연결하고 외부에 노출 (1) | 2020.10.11 |
| [k8s] 4. 디플로이먼트 - 레플리카셋, 파드 배포 관리 (0) | 2020.10.11 |
| [k8s] 2. 파드 - 컨테이너의 기본 단위 (0) | 2020.10.10 |





