
스프링에서 편리하게 Master / Slave 분기 처리하기
SightStudio
·2021. 8. 27. 03:07
도입
실제 서비스를 운영하다 보면 데이터베이스가 여러 개의 노드로 분산되어
Master / Slave (또는 Multi Master) 구조로 이루어져 있는 경우가 많습니다.
이때 어플리케이션 레벨에서 어떻게 DataSource를 분기처리 할 지 고민이 많았습니다.
이 경우에 크게 두가지 방법으로 나뉘는데요
1. RW / RO 별로 데이터소스를 만들어 개발자가 이를 인지하며 개발을 하거나
2. 단일 데이터 소스에서 트랜잭션의 분기처리를 Lazy 하게 처리하는 방법
으로 두가지가 있습니다.
저는 스프링의 [ AbstractRoutingDataSource ] 를 사용하여
2번 방법으로 진행하였으며, 코드는 [깃허브]에 있습니다.
먼저 결과를 알려드리자면, 2번 방식으로 진행했을 경우 아래와 같이 동작하게됩니다.

테스트 환경

테스트는 실제 운영 환경과 최대한 유사한 형태로 구성하였습니다.
Spring Boot 서버는 HAProxy를 통해 DB에 접근하게 됩니다.
스프링 서버가 HAProxy를 통해
1. 3306 포트에 접근할 경우 3308 포트의 Read - Write 노드에 접근
2. 3307 포트에 접근할 경우 3309, 3310 포트에 띄워져 있는 Read - Only 노드들에 접근하게 됩니다.
테스트는 JPA + QueryDSL을 통해 진행하였으며,
멀티 데이터베이스 환경에서 테스트를 하였습니다. ( board, user )
(멀티 데이터베이스에서 구성 해보면 싱글도 쉽게 할 수 있어서 위와 같이 구성하였습니다)
DB 설정 정는 아래와 같이 구성되어 있습니다.

방법 1. RW / RO 별 데이터 소스 정의
제일 간단한 방법으로는 어플리케이션 레벨에서 아래과 같이
개발자가 DataSource를 인지해가면서 처리를 하는 경우가 있는데요.
이럴 경우 몇가지 단점을 겪었습니다.

단점
1. 다른 노드 Undo 영역 참조 불가로 인한 문제
만약 다음과 같이 Read-Write 노드에서 유저를 새로 생성하고,
Read-Only 노드에서 전체 유저의 개수를 가져오면 어떻게 될까요?
Undo 영역은 노드간에 공유되지 않기 때문에 아래의 count는
커밋되지 않은 신규 유저 값을 제외하고 카운트하게됩니다.

2. DB 노드간 복제 지연으로 인한 Eventual Consistency 이슈

노드간 완전 동기화를 보장하는 MySQL 클러스터인 [ Galera Cluster ] 또한 노드간 복제 지연이 존재합니다.
그렇기 때문에 Read-Only 행위더라도 Read-Write 노드에서 쿼리를 실행해야 할 경우가 있습니다.
이 경우에도 개발자가 따로 비즈니스 로직에서 조건문을 통해 분기처리를 해야 했는데요.
이러한 경우를 겪으면서 DataSource를 하나만 쓸 수 없을까? 라는 의문으로
아래의 2번 방식을 적용해봤습니다.
방법 2. AbstractRoutingDataSource 사용
데이터 소스 설정이 장황합니다.
[코드] 는 링크에서 확인하시면 됩니다.
AbstractRoutingDataSource는 이러한 상황에서 현재 트랜잭션에 상태를 확인하여
여러 데이터 소스를 Lookup 하여 맞는 데이터 소스를 실행시킬 수 있게 합니다.
이를 통해 아래와 같이 Read-Write 데이터 소스와, Read-Only 데이터 소스를
하나의 데이터 소스로 통합하여 사용할 수 있도록 하였습니다.
다만 이 경우에는 트랜잭션이 시작하더라도 실제 쿼리 발생직전에 connection을 생성해야하기 때문에
AbstractRoutingDataSource를 상속받는 데이터 소스를
LazyConnectionDataSourceProxy 로 감싸야합니다.
LazyConnectionDataSourceProxy 는 트랜잭션 시작시 Connection Proxy 객체를 리턴하고
실제 쿼리를 실행할때가서야 데이터 소스에서 connection을 가져옵니다.
이렇게 해야만 readOnly 값을 통해 데이터 소스를 분기처리 할 수 있습니다.


주의
작업을 진행하다 보면 추가로 빈을 생성하지 않기 위해
다음과 같이 Route 데이터 소스에 직접 LazyConnectionDataSourceProxy 를 붙이고 싶은 욕구가 들텐데요
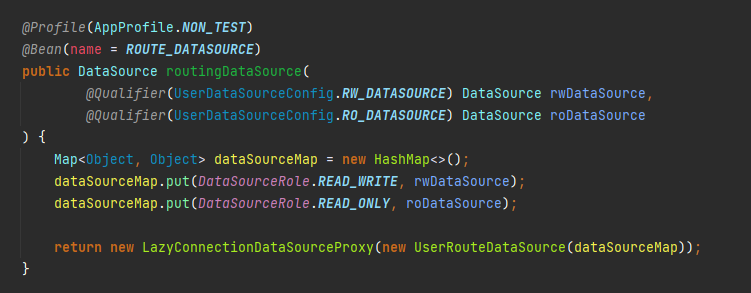
실제로 했다간 에러가 발생합니다.

이 부분은 AbstractRoutingDataSource 의 내부 코드를 보면 알 수 있는데요
"빈 최초 생성 시점" 에 RW/RO 데이터소스들을 등록하기 때문입니다.


이렇게 모든 설정을 마치면
다음과 같이 readOnly 속성으로만 분산 DB를 분기처리 할 수 있습니다.
장점
1. Spring Transaction의 Propagation 설정에 맞춰서 DB를 분기처리 할 수 있습니다.
2. 코드 레벨에서 분기처리를 하지 않기 때문에 더 유연한 구조를 가진 코드를 만들 수 있습니다.
3. 개발자가 실수 할 수 있는 여지를 원천적으로 차단합니다.
적용 확인
쿼리가 어디서 실행되는지 확인하기 위해 각 노드들의 MariaDB의 General Log를 활성화 한 채로
시스템 스키마의 general_log 테이블을 확인하였습니다. (mysql 스키마)
테스트 코드는 [여기] 있습니다.
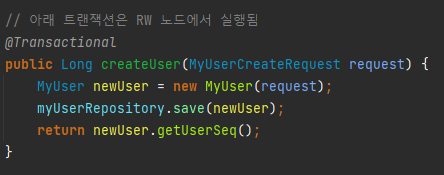
테스트 1. 신규 유저 생성
@Transactional의 Read-Only 속성은 디폴드가 false 이기 때문에
RW 노드에서 쿼리를 실행하는 모습을 볼 수 있습니다.


테스트 2. 유저 조회
@Transactional의 Read-Only 설정을 true로 설정 하고 확인한 결과
3309번 읽기 노드에서 쿼리가 실행된 것을 확인 할 수 있습니다.



테스트 3. 신규 유저 생성 후, 전체 유저 수 조회
다음은 신규 유저 생성 후, 전체 유저의 개수를 가져오는 쿼리입니다.
당연히 undo 영역을 참조해야하기 때문에 count() 또한 Read-Write 노드 에서 실행되어야합니다.
실제 쿼리 로그를 보면 insert, select 모두 RW 노드에서 실행된 것을 확인 할 수 있습니다.



마치며
이번 시간에는 AbstractRoutingDataSource + LazyConnectionDataSourceProxy 를 통해
코드 레벨의 수정없이 편리하게 분산 데이터베이스의 분기처리 하는 방법을 정리하였습니다.
'개발 > Spring' 카테고리의 다른 글
| jOOQ를 JPA와 같이 써보자 (9) | 2022.09.10 |
|---|---|
| [입문] jOOQ에 대해 알아보자 (3) | 2021.03.04 |
| JPA로 Type-Safe한 CTE 작성하기 (4) | 2021.02.21 |
| [Spring] Field Injection은 왜 나쁜가? (3) | 2020.08.16 |





