
Apache Airflow에 대해서 조금만 알아보자
SightStudio
·2025. 2. 22. 11:41


지난 2025.02.13 (목)에 아파치 에어플로우 밋업을 다녀왔습니다.
사실 그전까지 'Airflow라는 게 있다. 써보니 좋더라' 정도만 들었었고 정확히 어떤 기술인지 알지 못했는데요.
밋업에 대한 후기도 좋지만 Airflow에 대한 지식이 전무했어서, Airflow에 대해서 간략하게 알아보고
백엔드 조직에서 쓴다면 어떨지에 대한 고민을 해보았습니다.
Airflow 란?

Apache Airflow는 Airbnb에서 시작된 오픈소스 워크플로우 오케스트레이션 툴로, 아파치 재단에서 관리하고 있습니다.
데이터 파이프라인과 배치 작업을 정의, 스케줄링 및 실행하는 데 특화되어 있습니다.
아래 글을 참고하여 현시점 워크플로우 오케스트레이션 툴 중에서는
아파치 에어플로우가 제일 활발하고, 인기 있는 것을 확인할 수 있었습니다.
https://www.pracdata.io/p/state-of-workflow-orchestration-ecosystem-2025
State of Open Source Workflow Orchestration Systems 2025
Overview of Major 2024 Trends and Emerging Technologies Shaping 2025
www.pracdata.io
주요 컨셉
DAG(Directed Acyclic Graph)는 Airflow에서 워크플로우를 정의하는 핵심 개념으로서 방향 비순환 그래프를 말합니다.
DAG를 통해 여러 개의 Task 간의 실행 순서와 종속성을 정의할 수 있습니다.
그리고 무엇보다 DAG는 파이썬으로 작성됩니다.


Ariflow의 아키텍처
다음은 Airflow 아키텍처입니다. 생각보다 단순해서 어렵지 않습니다.

• Webserver
DAG, 태스크의 상태를 모니터링하고 트리거하기 위한 UI를 제공합니다.
Flask + Flask AppBuilder (FAB) 기반으로 이루어져 있어 app builder를 통해 커스텀한 view를 제공할 수 있습니다.
• DAG 파일 폴더
DAG 파일은 워크플로우의 실행 순서와 종속성을 정의하는 Python 코드입니다.
DAG 파일은 주기적으로 스케줄러가 로드하여 실행할 Task를 결정하며, 실행 상태는 Metadata DB에 저장됩니다.
• Scheduler
스케줄러는 DAG을 주기적으로 확인하고, 실행할 Task를 결정합니다.
Task가 실행될 시점이 되면 Executor를 통해 Worker에게 작업을 전달하며, 실행 상태를 Metadata DB에 기록합니다.
• 메타데이터 DB
DAG 정의, Task 실행 기록 등을 저장하며, Scheduler와 Web UI가 이를 기반으로 실행 상태를 관리합니다.
운영 환경에선 보통 PostgreSQL이나 MySQL로 사용합니다.
일단 한번 해보자
Airflow는 docker-compose로 로컬에서 구동시켜 볼 수 있습니다. [문서]
숫자 1,2,3,4를 배열로 입력받고
even_task에서는 짝수를, odd_task에서는 홀수를 출력하는 워크플로우를 작성해 보았습니다.
다음 조건도 추가해 보죠.
- 스케줄링: 매주 월요일 오전 10시에 실행
- 리트라이: 실패 시 5분 뒤에 1번만 재시도
코드는 접은 글에 있습니다.
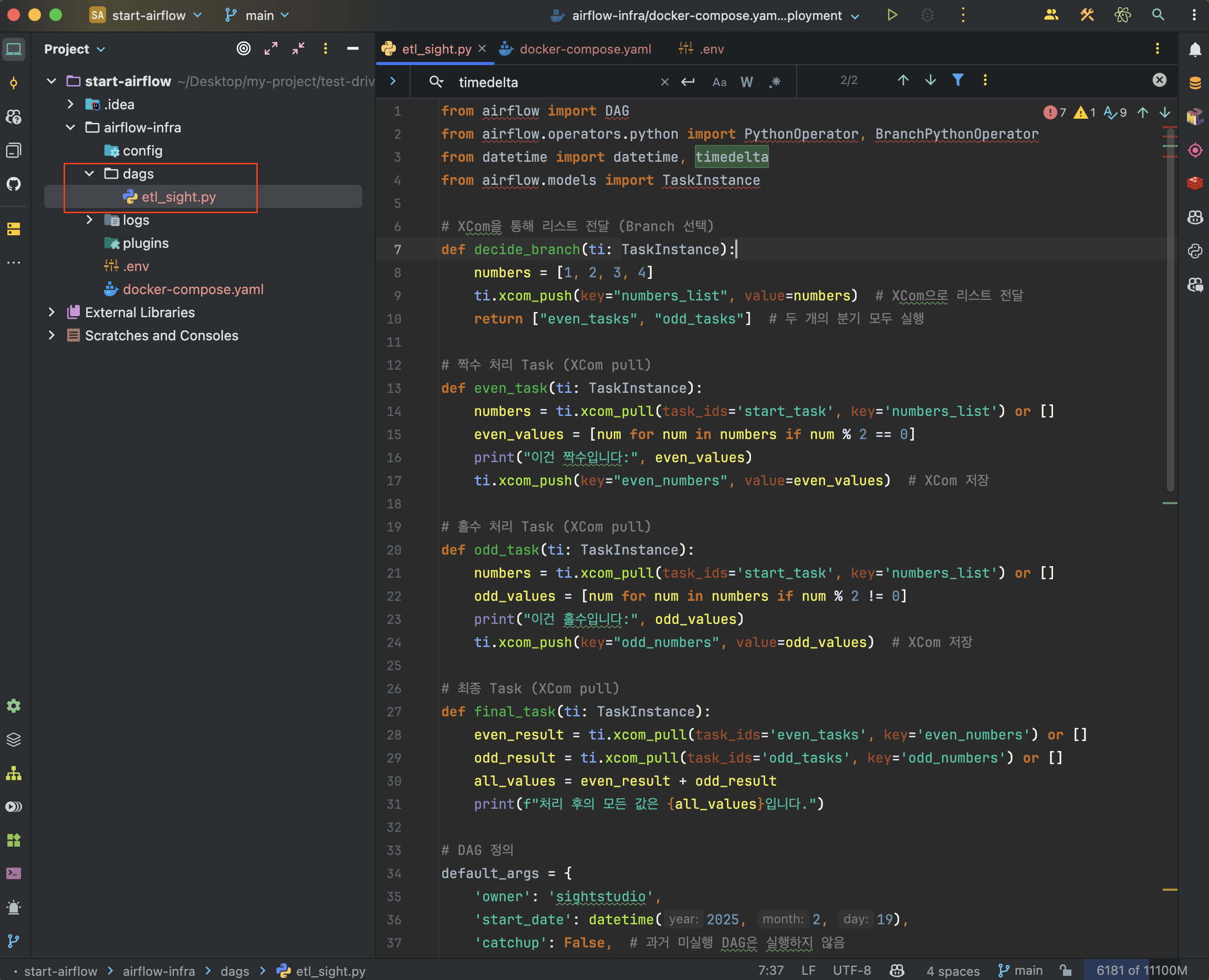
from airflow import DAG
from airflow.operators.python import PythonOperator, BranchPythonOperator
from datetime import datetime, timedelta
from airflow.models import TaskInstance
# XCom을 통해 리스트 전달 (Branch 선택)
def decide_branch(ti: TaskInstance):
numbers = [1, 2, 3, 4]
ti.xcom_push(key="numbers_list", value=numbers) # XCom으로 리스트 전달
return ["even_tasks", "odd_tasks"] # 두 개의 분기 모두 실행
# 짝수 처리 Task (XCom pull)
def even_task(ti: TaskInstance):
numbers = ti.xcom_pull(task_ids='start_task', key='numbers_list') or []
even_values = [num for num in numbers if num % 2 == 0]
print("이건 짝수입니다:", even_values)
ti.xcom_push(key="even_numbers", value=even_values) # XCom 저장
# 홀수 처리 Task (XCom pull)
def odd_task(ti: TaskInstance):
numbers = ti.xcom_pull(task_ids='start_task', key='numbers_list') or []
odd_values = [num for num in numbers if num % 2 != 0]
print("이건 홀수입니다:", odd_values)
ti.xcom_push(key="odd_numbers", value=odd_values) # XCom 저장
# 최종 Task (XCom pull)
def final_task(ti: TaskInstance):
even_result = ti.xcom_pull(task_ids='even_tasks', key='even_numbers') or []
odd_result = ti.xcom_pull(task_ids='odd_tasks', key='odd_numbers') or []
all_values = even_result + odd_result
print(f"처리 후의 모든 값은 {all_values}입니다.")
# DAG 정의
default_args = {
'owner': 'airflow',
'start_date': datetime(2025, 2, 19),
'catchup': False, # 과거 미실행 DAG은 실행하지 않음
'retries': 1, # 실패 시 1회 재시도
'retry_delay': timedelta(minutes=5), # 재시도 간격 (5분 후 재시도)
}
dag = DAG(
'even_odd_branching_xcom',
default_args=default_args,
schedule_interval="0 10 * * 1", ## 매주 월요일 10시
)
# Start Task (XCom을 사용하여 데이터 전달)
start = BranchPythonOperator(
task_id='start_task',
python_callable=decide_branch,
dag=dag
)
# 짝수 Task
even = PythonOperator(
task_id='even_tasks',
python_callable=even_task,
dag=dag
)
# 홀수 Task
odd = PythonOperator(
task_id='odd_tasks',
python_callable=odd_task,
dag=dag
)
# 최종 Task
final = PythonOperator(
task_id='final_task',
python_callable=final_task,
dag=dag
)
# DAG 실행 순서 정의
start >> [even, odd] >> final
DAG폴더에 해당 파이썬 파일을 추가하면, localhost:8080에서 해당 DAG가 노출되는 것을 확인할 수 있습니다.
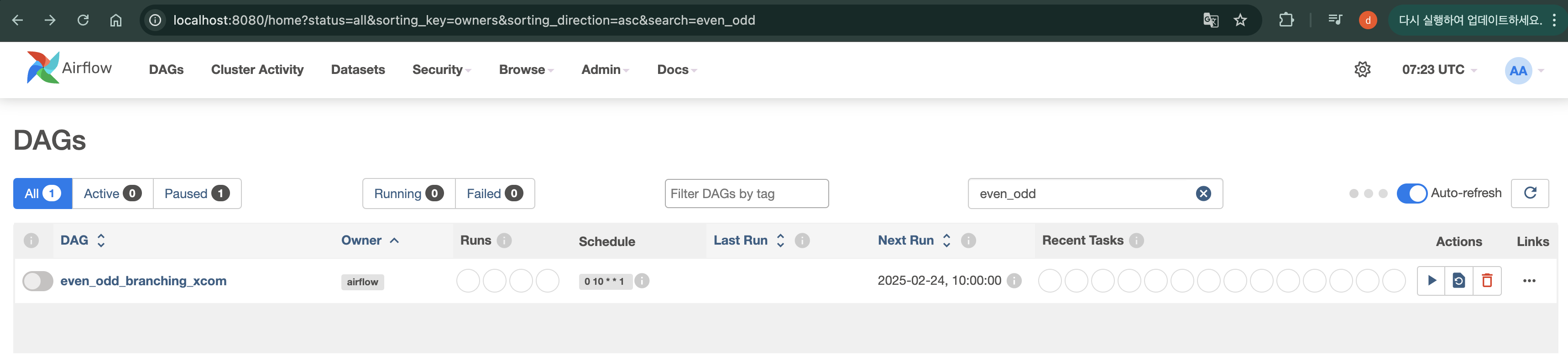

해당 DAG안으로 들어가면, DAG가 DAG Run (DAG가 실행된 단위)들이 기록으로 남아있는 것을 볼 수 있습니다.
DAG Run 안에 Task들의 상태까지도 관측할 수 있습니다.

여기에서 KubernetesPodOperator를 사용하면 특정 TASK의 자원을 제한하는 유연성을 제공할 수 있습니다.
그 외에도 다 향한 Operator들이 존재합니다.
| Operator 유형 | 설명 |
| Trigger / Sensor | 외부 이벤트를 감지하고 데이터 수집 (예: 파일 업로드 감지, API 응답 대기) |
| PythonOperator / BranchPythonOperator | 데이터 변환, 조건 분기 처리 (Python 코드 실행) |
| DatabaseOperator / BashOperator | 데이터 저장, API 호출, 파일 저장 등의 작업 수행 |
| DAG Task (PythonOperator) | 배치 실행, 데이터 파이프라인의 핵심 Task |
이걸 어디에 쓸 것인가?
Airflow를 사용해 보니 데이터 엔지니어링뿐 아니라 백엔드에서도 좋아 보인다는 생각이 들었습니다.
그런 의미에서 다른 기술들과 비교해 보았습니다.
비교대상
- k8s CronJob
- Jenkins Pipeline
- Spring Cloud Data Flow
배치 스케줄링과 성공 실패를 Airflow에서 관리한다면 관리포인트가 훨씬 줄일 수 있어 보입니다.
배치에서 필요한 다음과 같은 요건들을 충족시킬 수 있어 보입니다.
- 재시도 처리
- 배치 실행기록 (DAG Run 기록)
- RBAC 기반의 접근 권한제어
- 특정 배치는 별도 자원으로 단독실행 (서버리스?)
- 실패시 알림
특히 접근 권한제어, 배치 실행기록은 ITGC (정보기술일반통제)와 관련해서 반드시 요구되는 사항인데요.
실행기록등을 airflow에서 API로 export 할 수 있어서 이런 부분도 대응하기 쉬워 보입니다.

K8s CronJob
k8s환경에서는 배치 스케줄링을 k8s cronjob을 사용하는데요.
이렇게 k8s의 cronjob을 사용하면 여러 k8s 클러스터 간의 배치기록을 관리할 수 없고
curl로 배치를 트리거하는 정도의 작업밖에 불가능합니다. 배치의 성공, 실패 또한 파악하기 어렵습니다.
당연히 워크플로우도 기대할 수 없습니다.

Jenkins
역사와 전통의 젠킨스도 이런 배치 스케줄링, 워크플로우 작업을 할 수 있습니다.
당연히 플러그인을 통해 권한제어도 가능합니다.
다만 Jekins는 Task 별로 자원 할당이 불가능하고, 워크플로우에 대한 지원, 관측성도 부족합니다.
이런 CI/CD가 제외된 목적에서는 Jenkins를 사용할 이유가 많이 줄어듭니다.

다음은 위의 예시를 Jenkins Pipeline으로 변환한 groovy 코드입니다. (접은 글 참고)
개인의 차이는 있겠지만 groovy보단 python이 훨씬 작업하기 편해 보입니다 ㅎㅎ
pipeline {
agent any
environment {
EVEN_NUMBERS = ''
ODD_NUMBERS = ''
}
stages {
stage('Decide Branch') {
steps {
script {
def numbers = [1, 2, 3, 4]
env.NUMBERS_LIST = numbers.join(',')
echo "Numbers: ${env.NUMBERS_LIST}"
}
}
}
stage('Parallel Processing') {
parallel { // 분기문은 패러럴로..?
stage('Process Even Numbers') {
steps {
script {
def numbers = env.NUMBERS_LIST.split(',').collect { it as Integer }
def evenValues = numbers.findAll { it % 2 == 0 }
env.EVEN_NUMBERS = evenValues.join(',')
echo "이건 짝수입니다: ${evenValues}"
}
}
}
stage('Process Odd Numbers') {
steps {
script {
def numbers = env.NUMBERS_LIST.split(',').collect { it as Integer }
def oddValues = numbers.findAll { it % 2 != 0 }
env.ODD_NUMBERS = oddValues.join(',')
echo "이건 홀수입니다: ${oddValues}"
}
}
}
}
}
stage('Final Stage') {
steps {
script {
def allValues = (env.EVEN_NUMBERS.split(',') + env.ODD_NUMBERS.split(',')).findAll { it }
echo "처리 후의 모든 값은 ${allValues}입니다."
}
}
}
}
post {
success {
echo "파이프라인 성공적으로 완료됨!"
}
failure {
echo "파이프라인 실패. 로그를 확인하세요."
}
}
}
Spring Cloud Data Flow


SCDF 또한 Airflow와 유사하게 워크플로우를 만들 수 있습니다.
추가로 SCDF는 Spring 기반 애플리케이션에서 잘 어울리며, 실시간 스트리밍 및 배치 모두 지원하는 장점이 있습니다.
몇 개 비교해 보자면
재실행성
Airflow는 DAG에서 Task단위로 세밀하게 Retry 설정을 할 수 있지만
SCDF는 전체 배치 단위로 실패 감지 후 재실행할 수 있습니다.
관측성
또한 테스크들의 의존성이나 모니터링은 Airflow가 좀 더 편하다는 느낌을 받았습니다.
자바, Spring 연계
SCDF는 jar파일로 앱을 등록하고 이를 통해 Task들을 실행합니다.
즉 컴파일을 하고, Spring Batch를 사용할 수 있습니다. 자바 기반으로 코드를 작성할 수 있다는 게
스프링 진영에서는 꽤 괜찮은 선택지로 보이네요.
그리고 스트리밍이 지원된다는 점 또한 SCDF를 고려할만한 선택지로 만들어줍니다.
단순히 API로 배치 트리거링을 하는 것 이외 스프링 환경에서 스트리밍이나, 다른 작업이 많다면
SCDF도 좋아 보이네요 ㅎㅎ
결론
Airflow를 써보니 자바를 주력으로 쓰는 개발자임에도
간단한 파이썬 코드 작성으로 이 정도의 편리함을 느낄 수 있던 건
Airflow가 그만큼 잘 만든 좋은 기술이라는 증거로 생각됩니다.
배치와 워크플로우 오케스트레이션 툴은 팀의 상황에 따라 SCDF와 Airflow 중 하나를 선택해서 고를듯합니다.
이렇게 다른 기술과 비교해 보는 것을 마지막으로 글을 마치도록 하겠습니다.
'일상' 카테고리의 다른 글
| 사내시스템 도메인은 정말로 재미 없는가? (2) | 2024.06.28 |
|---|---|
| 이 사람은 뭘 하고 있나 (2023년 상반기? 회고) (2) | 2023.08.22 |
| 2022년 상반기 회고 (5) | 2022.03.27 |
| 퇴사를 했다 그런데 이제 이직을 곁들인 (0) | 2021.12.18 |
| [오픽] 첫 오픽 시험 IH 달성기 (3) | 2020.09.22 |





